How I saved 200 hours of Ellicium’s Recruitment Team Using Hadoop

Ellicium is growing at a fast pace. And as for every growing organization, talent hunt becomes the task with the highest priority.
When I joined Ellicium, it was still in its initial phase, where we were finding our space in the Big Data market. I have witnessed and been part of the Ellicium team with the zeal and passion to make a dent in the universe of Big Data. After executing and implementing some unique projects, Ellicium’s team size has increased 300%. One of the biggest challenges in this growth story has been to find the right candidate for the specific position. And many a time, I have seen recruitment teams struggle to shortlist candidates from the sea of applications.
Recently, we had several urgent open positions for which we wanted to hire candidates through a recruitment drive. To our surprise, we received a few hundred resumes. Taking the typical manual resume shortlisting approach would have cost us more than 200 human hours. We wanted to get the right candidates fast. As the human resource team was mulling over the approach to pull this gigantic task, I stepped in!
For one of the Big Data implementations, there was a similar client requirement, where they struggled to search business-critical data from a huge amount of unstructured data stored in the form of files. I used Apache Tika, Apache Solr, Cloudera Search, and HDFS from the Hadoop framework for that implementation.
Below is the architecture diagram of our Approach

Details of Resume Shortlisting Using Big Data Technologies
Our recruitment team had stored received resumes in local machines. First and foremost, I migrated all these files from local machines to HDFS. Then, I used Apache Tika to convert outlines into text files and to extract metadata information from those files. This is a vital preparatory stage, as data gathered here becomes an input for further process.
Once I had metadata information for all files, Apache Solr indexed the files as shown in the diagram. Apache Solr offers neat and flexible features for search. Required parameters from the extracted metadata must be given to Apache Solr for indexing. These parameters include file name, file ID, size of the file, author, date when it was created, and last modified.
All this speeds up the file search on a specific query.
We used Cloudera search to make search more user-friendly for a non-technical user. The Cloudera search has a more presentable GUI, where you can easily put your query and get the results. In our case, it helped us to shortlist resumes with the required skill sets. For example, I want to find resumes with Java skills. I will just put these two keywords in the Cloudera search text box, and as a result, I will get all the relevant resumes for direct download.
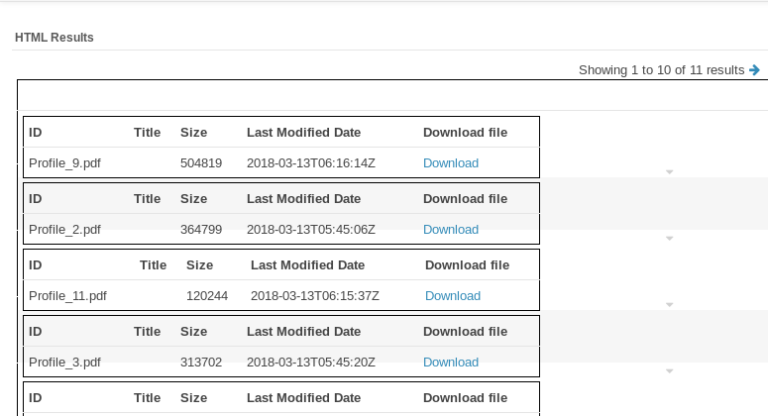
Picture 1: All Resumes
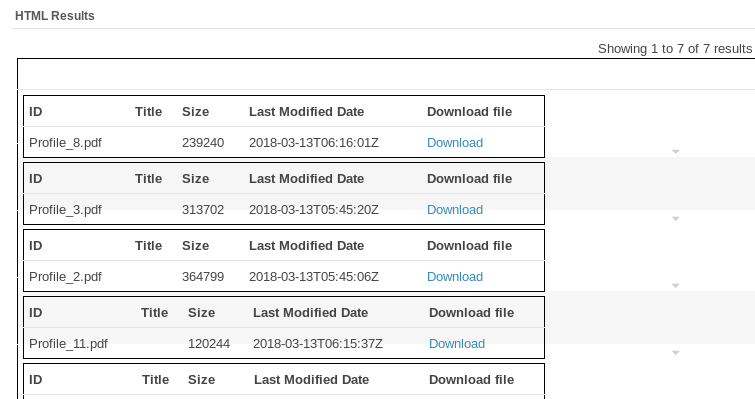
Picture 2: Resume Shortlisted For Java
Use of HUE GUI
Going one step further, we created dashboards to perform analytics on received resumes using HUE GUI. For example, assume that I want to know how many of the received resumes have mentioned Python as a skill. I will use the pie chart utility in the HUE to visualize it.
Against the manual method, resume shortlisting became a one-click task using the above approach. We saved almost 200 human working hours. Above all, it made our recruitment process fast! New Ellicians will join us soon.
Given the exponential growth of unstructured data, this approach can have many applications. Whether searching for inventory information documents in the retail industry or finding the medical history of a specific patient from a huge number of reports, this approach is a lifesaver!
This Resume Shortlisting implementation will soon be a part of Ellicium’s Gadfly platform. ‘Gadfly’ is an analytics platform for unstructured data.