Stop Wasting Time: Web Scraping with Synchronous Python Code

Is your Python web scrapping code taking a very long time to download the content? Are you trying to find solutions to optimize your code? You might think of using Multiprocessing or Multithreading, but the most helpful technique in such scenarios is using asynchronous code.
Let me explain the difference between synchronous coding and asynchronous coding so that one can better understand how time is properly utilized using asynchronous coding. Let us assume a scenario where data is scrapped from multiple pages using the requests library in python.
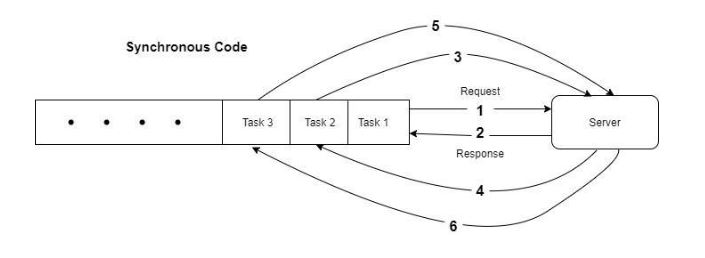
In the above fig., as you can see, each task requests the server and will have to wait for the response from the server. Currently, the CPU resources are idle until the response has been received. After this, only the next task can make a request. In Asynchronous code, this is different. Asynchronous code takes advantage of the idle time between sending the request and waiting for the response. This is shown in fig.
As we can see in asynchronous code, the individual tasks do not wait for the task’s response ahead of it. The requests are made by the tasks simultaneously, one after the other. When all the tasks have made requests, the time server sends the response as they are ready. The responses are received in a different manner than they have been sent.
Rather they are received when they are ready. Hence in fig. It is mentioned as “ND” (Order is not defined.).But one as a programmer does not have to think about the order in which responses are received, python language orders it in the manner as they were sent. One can see a drastic difference in the execution time of synchronous and asynchronous code if tasks are very large in number.
Python supports asynchronous web scrapping, which can be achieved using the libraries async io and aiohttp. Let us see a practical demo of Synchronous Vs Asynchronous coding in python.
The use case is to scrape data from multiple URLs.
Synchronous Python Code using requests. Import requests import time.
def scrape():
text_list = []
for number in range(500):
url = f”url_to_scrape_{number}”
resp = requests.get(url)
resp_text = resp.text
text_list = text_list.append(resp_text)
return text_list
if “__name__” == “__main__”:
start = time.time()
text_list = scrape()
print(f”time required : {time.time() – start} seconds”)
Asynchronous Python code :
import asyncio
import aiohttp
import time
async def get_content(session, url):
async with session.get(url) as resp:
text = await resp.text()
return text
async def scrape():
async with aiohttp.ClientSession() as session:
tasks = []
for number in range(500):
url = f”url_to_scrape_{number}”
tasks.append(get_content(session, url))
text_list = await asyncio.gather(*tasks)
return text_list
if “__name__” == “__main__”:
start = time.time()
text_list = asyncio.run(scrape())
print(f”time required : {time.time() – start} seconds”)
You can use the async code template above and modify it according to your need. Try executing both of the above codes (Just remember to change the URL and manipulate the response as per need) for many URLs, and you will notice a large execution time difference in both codes.
You can see Asncio documentation at “https://docs.python.org/3/library/asyncio.html”