Structure of Parquet File Format

I explained the ORC file structure in my previous article (Read here – All you need to know about ORC file structure in depth). It received a tremendous response, pushing me to write a new article on the parquet file format.
In this article, I will explain the Parquet file structure. After this article, you will understand the Parquet File format and stored data. Apache Parquet is a free and open-source column-oriented data storage format of the Apache Hadoop ecosystem. It is similar to the other columnar-storage file formats available in Hadoop: RCFile and ORC.
Parquet file format consists of 2 parts –
- Data
- Metadata
Data is written first in the file, and the metadata is written at the end for single-pass writing. Let’s see the parquet file format first, and then let us have a look at the metadata.
File Format
A sample parquet file format is as follows –
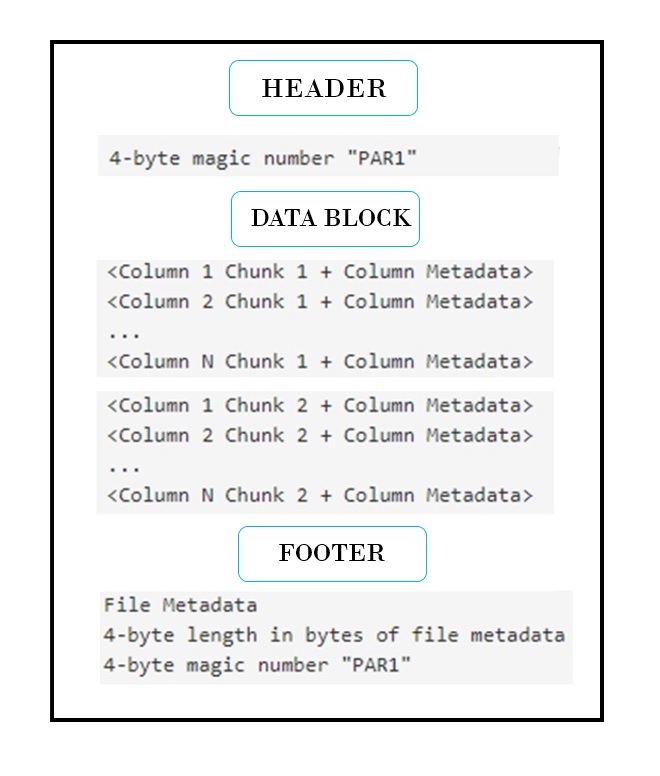
HEADER
At a high level, the parquet file consists of a header, one or more blocks, and a footer. The parquet file format contains a 4-byte magic number in the title (PAR1) and at the end of the footer. This magic number indicates that the file is in parquet format. All the file metadata is stored in the footer section.
Later in the blog, I’ll explain the advantage of having the metadata in the footer section.
DATA BLOCK
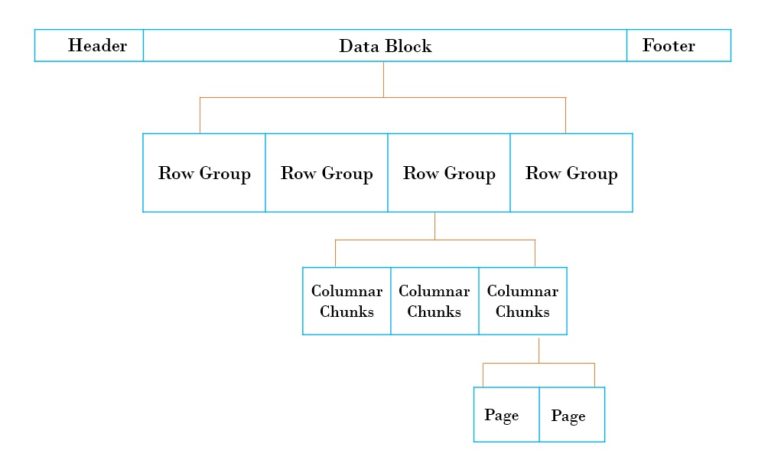
Blocks in the parquet file are written in the form of a nested structure as below –
—Blocks
—Row Groups
—–Column Chunks
———Page
Each block in the parquet file is stored in the form of row groups. So, data in a parquet file is partitioned into multiple row groups. These row groups, in turn, consist of one or more column chunks that correspond to a column in the data set. The data for each column is written in the form of pages. Each page contains values for a particular column only, hence pages are very good candidates for compression as they contain similar values.
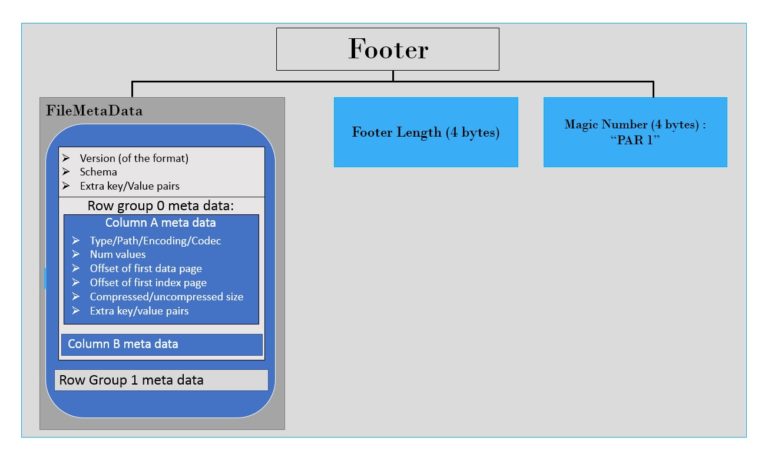
FOOTER
As seen above, the file metadata is stored in the footer.
The footer’s metadata includes the version of the format, the schema, any extra key-value pairs, and metadata for columns in the file. The column metadata would be type, path, encoding, number of values, compressed size, etc. Apart from the file metadata, it also has a 4-byte field encoding the length of the footer metadata and a 4-byte magic number (PAR1)
In the case of Parquet files, metadata is written after the data is written to allow for single-pass writing.
Since the metadata is stored in the footer, while reading a parquet file, an initial seek will be performed to read the footer metadata length, and then a backward seek will be committed to read the footer metadata.
In other files like Sequence and Avro, metadata is stored in the header, and sync markers are used to separate blocks, whereas, in Parquet, block boundaries are directly stored in the footer metadata. It is possible to do this since the metadata is written after all the blocks have been reported.
Therefore, parquet files are split-able since the block boundaries can be read from footer metadata, and blocks can quickly locate and process in parallel. Hope this provides a good overview of the Parquet file structure.