Things to do to get the Best Performance from HBase

This HBase performance tuning article results from several implementations we have done over the period. We can now confidently narrate a few points that, if implemented correctly, can make HBase very efficient and work as per your requirements.
Any discussion on Big Data invariably leads to Hadoop. However, another approach for effectively managing Big Data is using NoSQL databases, which are becoming mainstream. Various NoSQL databases, including Cassandra, MongoDB, CouchDB, Neo4j, Accumulo, MarkLogic, Redis, and HBase, are widely used today.
HBase holds a very important place in the list of NoSQL databases as it works on Hadoop by using HDFS as the underlying data store.
HBase is widely in use for a variety of use cases. Though HBase and other NoSQL databases are getting deployed in production, SQL is still the most preferred way to access databases for the end user of data. Using SQL layers such as Hive, Impala, or, more recently, Phoenix for querying HBase is inevitable.
Over the last couple of years, we have experienced a variety of scenarios in querying HBase databases using SQL engines, and every time, the question that comes to the fore relates to the things to be done to improve the performance of an HBase database. Having done several implementations, we can confidently list down a few points which, if implemented correctly, can make HBase very efficient and work as per your requirements –
- Define and use the Rowkey in the right manner.
- Use compression of data
- Use Bloom Filters
Define and use Rowkey in the right manner is Rowkey important
Rowkey forms the crux of storing and accessing data for any HBase database. HBase is optimized for reads based on the row key when data is queried. Query predicates are applied to row keys as start and stop keys. Query engines such as Impala, Hive, and BigInsights reading data from HBase translate predicates against efficient row key lookup when operators such as =, <, and BETWEEN are applied against the row key. Reading data from HBase based on a row key is similar to using an index for reading an RDBMS table. If you use the index in your query, you read only the required records; otherwise, you scan the entire table, which could be more efficient.
Use Case
In one of the implementations, the HBase table contained 50 million records, and the query was written to retrieve 10 records. We were using Impala external tables to read HBase. One would expect this query to be very fast, but it took a long time. We noticed that the query had used the ‘LIKE’ condition against the row key, so the predicate was not getting pushed down against the row key. HBase was scanning millions of records and then returning 10 records. Changing ‘LIKE’ to ‘BETWEEN’ did the magic, and the query execution time came down from 2 minutes to 1.5 seconds.
Let us get down to details as to why this happened.
Our HBase table was a time series table with “Parameter”,” Value,” and “Timestamp” as columns. The row key was a concatenation of “Parameter-Timestamp”. An external table was created in Impala against this HBase table with columns “Rowkey,” Parameter,” Value,” and “Timestamp”. Rowkey was defined as a string column. Our query objective is to find the sum of values for a specific parameter (say P11) for a specific range of timestamps.
All the below queries resulted in an HBase table scan and performed inefficiently.
SELECT SUM(VALUE) FROM TABLE WHERE PARAMETER = ‘P11’ AND TIMESTAMP BETWEEN ‘T1’ AND ‘T2’; (rowkey not used)
SELECT SUM(VALUE) FROM TABLE WHERE ROWKEY LIKE ‘P11%’ AND PARAMETER = ‘P11’ AND TIMESTAMP BETWEEN ‘T1’ AND ‘T2’;
The correct query to make use of row key lookup is like this:
SELECT SUM(VALUE) FROM TABLE WHERE ROWKEY BETWEEN ‘P10’ AND ‘P12’ AND PARAMETER = ‘P11’ AND TIMESTAMP BETWEEN ‘T1’ AND ‘T2’;
Similarly, comparing rowkey against a nonconstant value will result in scanning the entire table.
Summary
If you plan to scan the entire HBase table or most of it, you probably use HBase for the wrong purpose. HBase is most efficient for reading a single row or a range of rows.
If you are not using a filter against the row key column in your query, your row key design may need to be corrected. The row key should be designed to contain the information you need to find specific subsets of data.
When creating external tables in Hive / Impala against HBase tables, map the HBase row key against a string column in Hive / Impala. If this is not done, the row key is unused in the query, and the entire table gets scanned.
Carefully evaluate your query to check if it will result in row key predicates. Use of “LIKE” against the row key column does not result in a rowkey predicate, and it results in scanning the entire table.
The obvious question for a developer will be, ‘How do I know whether I am writing the correct query against a table’? This can be answered using the “Explain Plan” feature in Hive / Impala to evaluate query behavior.
Use Compression of HBase Tables
Why is Compression Important
Disk performance is almost always a bottleneck in Hadoop clusters. This is because Hadoop and HBase jobs are data-intensive, thus making data reads a bottleneck in the overall application. By using compression, the data occupies less space on the disk. Therefore, the process of reading data must take place on smaller, compressed data sizes. This leads to increased performance of reads. On the other hand, with compression comes the need to un-compress the data after reading, which increases CPU load.
3 compression algorithms can be applied to HBase data: LZO, GZIP, and Snappy. GZIP compression uses more CPU resources than Snappy or LZO but provides a higher compression ratio. GZIP is often a good choice for cold data accessed infrequently. Snappy or LZO is a better choice for hot data accessed frequently.
Use Case
We performed a benchmarking of compression performance using Snappy compression. For this, we used airline traffic data. About 5 million records from this dataset get loaded in the HBase table. We created 2 tables. One was without compression, and the second table was with Snappy compression. An external table in Impala was on top of the HBase table, and a set of queries to execute on both tables.
We executed the following queries on the data:
Query 1 – select dayofmonth, avg(deptime) from airline1 group by dayofmonth;
Query 2 – select DayofMonth ,sum(deptime) from airline2 where DayofMonth in (12,18) and month in (1,4,6,9) group by DayofMonth ;
All other parameters of the system (for example, number of nodes, memory, CPU, etc.) remained unchanged.
Results
The following readings were obtained after 7 distinct executions of each query.

A typical question is whether compression is used after data is loaded in HBase.
You can! You can alter the table containing data; the next time major compaction takes place, new compression will be applied to the table. Major compaction does a clean-up of StoreFiles and ensures that all data owned by a region server is local to that server.
Thus, we observed that Snappy compression increases the read performance by 14% for the first and 8% for the second queries. Therefore, overall, there was a performance gain observation of about 11% using Snappy compression.
After testing on test data of about 10 GB, we implemented the compression on the streaming data Hbase table in production. We observed a performance gain in line with the above experimental results.
Use Bloom Filters
What is a Bloom Filter
An HBase Bloom Filter is an efficient mechanism to test whether a StoreFile contains a specific row or row-column cell. Without Bloom Filter, the only way to decide if a row key is present in a StoreFile is to check the StoreFile’s block index, which stores the start row key of each block in the StoreFile. Bloom Filters provides an in-memory structure to reduce disk reads to only the files likely to contain that row. In short, it can be considered an in-memory index to determine the probability of finding a row in a particular StoreFile.
If your application modifies all or the majority of the rows of HBase on a regular basis, the majority of StoreFiles will have a piece of the row you are searching for. Thus, Bloom filters may only help a little. In the case of time series data, we update only a few records at a time, or when data is updated in batches, each row is written in a separate Storefile. In this case, the Bloom filter helps improve the performance of HBase reads by discarding Store files that do not contain the searched row.
Use Case
We used airline traffic data for experiments on the Bloom filter. About 5 million records from this dataset were loaded in the HBase table. The following are the results:
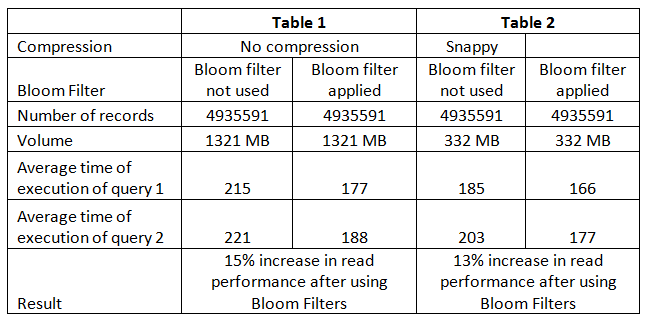
After testing the above settings on test data of about 10 GB, we implemented the same in streaming data HBase database. We observed a performance gain in line with the above experimental results.
As you will notice, one can improve the performance of HBase by implementing the above points related to Rowkey, Compression, and Bloom Filters.