How Did we solve the challenge of dynamic Hadoop configuration in Talend?

We recently helped a leading telecom company build a Data Lake in Hadoop to implement analytics. The use case involved the migration of terabytes of data from the Oracle database to Hive using Talend. It involved complicated business rules as data was sourced from varied sources like Oracle, ERP systems, and flat files. The objective was to do migration using a robust and configurable tool.
Our Talend Job Design
Our Talend jobs are designed in the following way –
- A joblet is used to pick up dynamic parameters from configuration tables. These included all the custom values that must be changed between environments.
- A parent job (Talend Standard Job) picks up data from the required sources and writes it to an intermediate file on HDFS.
- A child job (Spark Batch Job) is then triggered to copy the data from that intermediate file to a Hive-managed table in parquet format.
The challenge of Hadoop Cluster Configuration in Talend
The challenge in this migration process was to customize the cluster configuration. In the absence of such a custom configuration, Talend uses its own default Hadoop configuration. This causes problems when used with Hadoop clusters set up differently from what Talend expects.
Typically, Hadoop parameters differ for different environments like development, pre-production, and production. Examples are Key tab, Kerberos, resource manager, high availability properties, failover nodes, etc. Hence, these parameters must be manually changed when code moves across environments.
However, we were looking for a solution allowing the code to be migrated across environments without manually changing the parameters.
We temporarily achieved that by passing a .jar file to the job, which contained XML files from the cluster containing the required configuration. However, this jar file would have to be changed, and the job would have to be rebuilt every time the configuration changes or the position would have to be migrated to a different environment.
This was unsuitable for our use case, so we considered different approaches to overcome the problem.
Selecting the Best Approach to get over the Roadblock
After considering many scenarios, we zeroed down on the top three approaches. As explained below, we tried all these three approaches.
Approach 1: Changing the Custom Configuration
We considered an approach where different.jar files were used based on the environments. We created 2 context groups and could pass –context=Prod or –context=Dev depending on the .jar file we wanted to load. This approach partially worked, but the child job could not dynamically receive that context group’s value. Dynamic context can be passed to standard jobs, not big data jobs.
Furthermore, it would involve rebuilding whenever we had to change the configuration.
Approach 2: Manually Adding Custom Properties
There were 226 properties for the Talend job in the cluster configuration that needed customization for successful data migration. In this approach, we manually added these properties to the Hadoop components in the Talend job. We could change properties related to High Availability (HA) and Key Management Servers (KMS), which involved 17 properties in total.
This fixed the parent job, and we could write the file to HDFS. However, the child job failed even after adding all 226 properties! We even discussed this with Talend support, and they needed help to provide a reason or a solution. Hence, this approach was also discarded.
Approach 3: Removing the child job and creating an external table
After considering the above two approaches, we returned to the drawing board and put together an innovative approach. It took a lot of exciting discussions with our Big Data experts to find a way that fits the bill.
In this approach, the location of the intermediate file on HDFS was used as the directory for external Hive tables. Moving data from the HDFS file to the managed Hive table was no longer required, so we discarded the Big Data child job. This worked! With this approach, we reduced the build size by 90% since additional Hive and Spark libraries were no longer required. This also improved performance since the second step was eliminated. Even though we didn’t make the job completely dynamic, we completed our functional objective.
Below is the diagram explaining the approach:
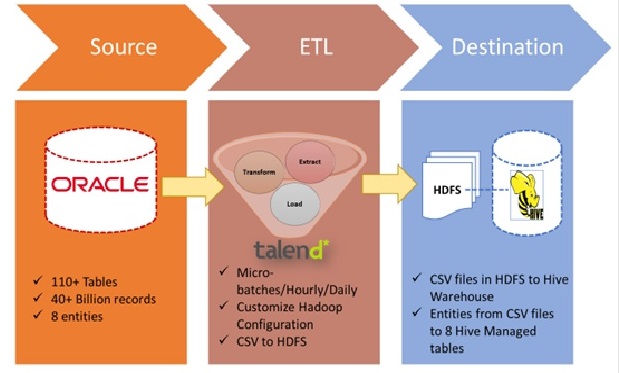
Though dynamic configuration is available in Talend, it does not work as expected. Talend needs to make the Hadoop components more configurable for Big Data jobs. At the same time, we would like to mention that Talend is moving in the right direction regarding the Big Data landscape. We solved the challenge of dynamic Hadoop configuration in Talend?